
بسم الله الرحمن الرحيم، الحمد لله الذي علم بالقلم، علم الإنسان مالم يعلم والصلاة والسلام على خير معلم الناس الخير محمد أما بعد:
مقدمة:
AWK هي لغة برمجة مفسرة مصممة لمعالجة النصوص وإنشاء التقارير. يتم استخدامه عادةً لمعالجة البيانات، مثل البحث عن العناصر داخل البيانات، وإجراء العمليات الحسابية، وإعادة هيكلة البيانات الأولية لإنشاء التقارير في أنظمة التشغيل Linux.
الاستخدامات النموذجية لـ AWK:
يمكن إنجاز عدد لا يحصى من المهام باستخدام AWK، سنعرض عدد قليل من هذه الاستخدامات:
- معالجة النصوص.
- إنتاج تقارير نصية منسقة.
- إجراء عمليات حسابية.
- إجراء عمليات على السلاسل النصية.
طريقة عمل AWK:
لكي نصبح على دراية في AWK ومعرفة قوية فأنت بحاجة إلى معرفة مكوناته الداخلية، هو يتبع سير عمل بسيط هو:
القراءة :arrow_left: التنفيذ :arrow_left: التكرار :recycle:
يوضح المخطط Flowchart التالي سير عمل AWK:
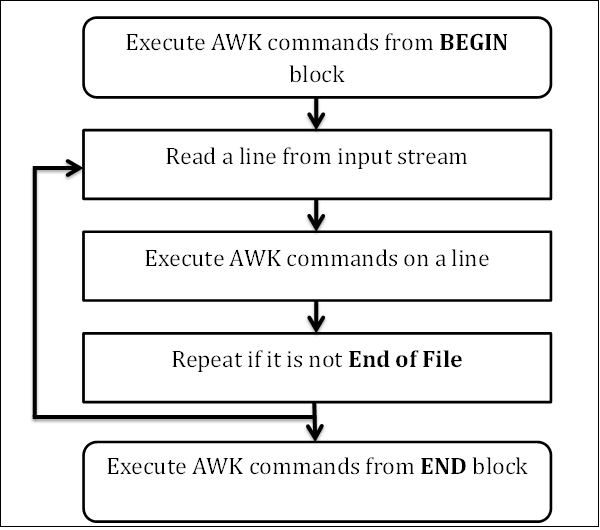
هنالك خمس كتل حسب المخطط Flowchart وهي:
BEGIN: يتم تنفيذ هذه الكتلة عند بدء تشغيل البرنامج فقط، ويتم تنفيذه مرة واحدة، تعتبر هذه الكتلة اختيارية،BEGINهي كلمة رئيسية فيAWKوبالتالي يجب أن تكون بأحرف الكبيرة.Read: هذه الكتلة مهمتها قراءة سطراً واحداً من المدخلات ويخزنه في الذاكرة.Execute: تنفيذ أوامرAWKعلى السطر الحالي، ويكون التنفيذ حسب تسلسل الأوامر التي كتبتها.Repeat: تكرار هذه العملية وأعني كتلةReadثمExecuteوهكذا حتى يصل الملف إلى نهايته ثم ينتقل للكتلة الأخيرة.END: يتم تنفيذ هذه الكتلة في نهاية البرنامج فقط، تعتبر هذه الكتلة اختيارية،ENDهي كلمة رئيسية فيAWKوبالتالي يجب أن تكون بأحرف كبيرة.
الطريقة النحوية لكتابة الأمر awk:
awk 'BEGIN {start_action} /pattern/ { actions } END {stop_action}' filename
awk '
BEGIN {start_action}
/pattern/ { actions }
/pattern/ { actions }
....
END {stop_action}
' filename
لنقم بإنشاء ملف words.txt يحتوي على الجملة التالية فقط Hollow World! للتأكد نقوم بعرض محتويات الملف عبر الأمر cat:
cat words.txt
Hollow World!
البدء باستخدام awk:
طباعة محتويات الملف:
awk '{print}' words.txt
Hollow World!
طباعة سطر قبل وبعد محتويات الملف:
لنقم بتجربة استخدام الكتلة BEGIN و END عبر كتابة جملة Start Line قبل محتويات الملف و End Line بعد طباعة الملف:
awk 'BEGIN{printf "Start Line\n"} {print} END{printf "End Line\n"}' words.txt
Start Line
Hollow World!
End Line
ملاحظة: استخدمنا \n لنقل مؤشر الكتابة في سطر جديد.
كتابة البرنامج النصي في ملف منعزل:
قم بإنشاء ملف نصي ليكن باسم command.awk وضع بداخله البرنامج أعلاه:
BEGIN{printf "Start Line\n"} {print} END{printf "End Line\n"}
الآن ما نحاول القيام به هو نفس الأمر السابق طباعة سطر قبل وبعد محتويات الملف words.txt ولكن سيكون برنامجنا مكتوب بداخل الملف command.awk:
awk -f command.awk words.txt
استخدمنا الخيار -f ﻹمكانية استدعاء مسار سكربت awk.
طباعة الأعمدة:
نقوم بإنشاء ملف نصي باسم marks.txt يحتوي على المعلومات التالية:
1) Amit Physics 80
2) Rahul Maths 90
3) Shyam Biology 87
4) Kedar English 85
5) Hari History 89
awk -F " " '{print $3 "\t" $4}' marks.txt
Physics 80
Maths 90
Biology 87
English 85
History 89
تم طباعة العامود الثالث والرابع فقط.
-Fللفصل بين الكلمات من خلال الفراغ space وبإمكانك تغير ذلك حسب النص المراد التعامل معه، نستطيع عدم وضع-Fلأن الأمرawkبأخذ بشكل افتراضي الفراغ للفصل بين الكلمات.$0: يعبر عن الصف (السطر) بشكل كامل.$1: تعبر عن الكلمة الأولى.$2: تعبر عن الكلمة الثانية، وهكذا.
طباعة السطور التي تحتوي على حرف a:
بشكل افتراضي يطبع awk جميع الأسطر التي تطابق النمط.
ملاحظة: عند عدم كتابة الأمر {print $0} يتم اتخاذ الإجراء الافتراضي وهو طباعة السجل.
awk '/a/ {print $0}' marks.txt
awk '/a/' marks.txt
2) Rahul Maths 90
3) Shyam Biology 87
4) Kedar English 85
5) Hari History 89
طباعة العمود 4 و 3 من السطور التي تحتوي على حرف a:
awk '/a/ {print $4 "\t" $3}' marks.txt
90 Maths
87 Biology
85 English
89 History
طباعة عدد السطور المطابقة للبحث:
/a/: البحث في كل سطر يحتوي على حرفa,{++i}: عدد السطور المطابقة.
ملاحظة: بإمكاننا تغير اسم العداد من i إلى أي شيء نريده.
awk '/a/{++i} END {print "Count = ", i}' marks.txt
Count = 4
المتغيرات المضمنة في awk:
المتغير ARGC:
يشير إلى عدد المعطيات المقدمة إلى awk.
awk 'BEGIN {print "Arguments =", ARGC -1 }' One Two Three Four
المتغير ARGV:
مصفوفة تخزين معطيات سطر الأوامر، فهرس المصفوفة من 0 حتى ARGC.
awk 'BEGIN {
for (i = 0; i < ARGC; ++i) {
printf "ARGV[%d] = %s\n", i, ARGV[i]
}
}' one two three four
ARGV[0] = awk
ARGV[1] = one
ARGV[2] = two
ARGV[3] = three
ARGV[4] = four
المتغير ENVIRON:
للتعامل مع متغيرات البيئة environment variables.
awk 'BEGIN { print ENVIRON["USER"] }'
المتغير FILENAME:
يمثل اسم الملف الحالي.
awk 'END {print FILENAME}' marks.txt
marks.txt
ملاحظة: وضعناFILENAME في بعد كتلة END حتى لا يتكرر طباعة اسم الملف بعدد سطور الملف.
المتغير FS:
يمثل فاصل المدخلات وقيمته الافتراضية هي space. يمكنك أيضًا تغيير هذا باستخدام خيار سطر الأوامر -F، افتراضيًّا يستخدم الفواصل whitespaces (المسافات spaces، tabs، إلخ) للفصل بين الأعمدة.
awk 'BEGIN {print "FS = " FS}' | cat -vte
المتغير NF:
يمثل عدد الأعمدة في السطر الحالي. على سبيل المثال، يطبع المثال التالي فقط تلك الأسطر التي تحتوي على أكثر من عمودين.
echo -e "One Two\nOne Two Three\nOne Two Three Four" | awk 'NF > 2'
المتغير NR:
يمثل رقم السطر الحالي. على سبيل المثال، يقوم المثال التالي بطباعة السطر إذا كان رقم السطر الحالي أقل من ثلاثة.
echo -e "One Two\nOne Two Three\nOne Two Three Four" | awk 'NR < 3'
المتغير OFS:
يمثل الفاصل بين المخرجات وقيمته الافتراضية هي space.
awk 'BEGIN {print "OFS = " OFS}' | cat -vte
المتغير RS:
يمثل فاصل سجل المدخلات وقيمته الافتراضية هي سطر جديد.
awk 'BEGIN {print "RS = " RS}' | cat -vte
المتغير RSTART:
يمثل مكان المحرف الأول في النص الذي يتطابق مع كلمة البحث:
awk 'BEGIN { if (match("One Two Three", "Thre")) { print RSTART } }'
المتغير $0:
يمثل السطر بأكمله.
awk '{print $0}' marks.txt
المتغير $n:
يمثل العمود الحالي، نقوم باستبدال n بالرقم الذي نريده حسب عدد الأعمدة، ويتم الفصل بين الكلمات بناء على المتغير FS.
awk '{print $3 "\t" $4}' marks.txt
المثال أعلاه سيقوم بطباعة العامود الثالث والرابع ويفصل بينهما بالتاب.
المتغير ARGIND:
يمثل فهرس الملف الذي يتم معالجته حالياً.
awk '{
print "ARGIND = ", ARGIND; print "Filename = ", ARGV[ARGIND]
}' junk1 junk2 junk3
المتغير IGNORECASE:
يجعل AWK غير حساس لحالة الأحرف لأجل المطابقة.
awk 'BEGIN{IGNORECASE = 1} /amit/' marks.txt
1) Amit Physics 80
المعاملات Operators:
تدعم AWK الكثير من Operators حالها كحال لغات البرمجة الأخرى.
المعاملات الحسابية:
الجمع:
awk 'BEGIN { a = 50; b = 20; print "(a + b) = ", (a + b) }'
(a + b) = 70
قمنا بإنشاء متغير a,b وأسندنا لهم الأرقام، ومن ثم طبعنا رسالة خرج مع القيام بجمع المتغيرين مع بعضهم.
الطرح:
awk 'BEGIN { a = 50; b = 20; print "(a - b) = ", (a - b) }'
الضرب:
awk 'BEGIN { a = 50; b = 20; print "(a * b) = ", (a * b) }'
القسمة:
awk 'BEGIN { a = 50; b = 20; print "(a / b) = ", (a / b) }'
باقي القسمة:
awk 'BEGIN { a = 50; b = 20; print "(a % b) = ", (a % b) }'
معاملات الزيادة والإنقاص:
الزيادة:
يتم تمثيله بـ ++ يقوم بالزيادة بمقدار 1، طريقة عمله هو إرجاع القيمة ثم الزيادة.
awk 'BEGIN { a = 10; b = a++; printf "a = %d, b = %d\n", a, b }'
a = 11, b = 10
الزيادة المسبقة:
يتم تمثيله بـ ++ يقوم بالزيادة بمقدار 1، طريقة عمله هو الزيادة ثم إرجاع القيمة المتزايدة.
awk 'BEGIN { a = 10; b = ++a; printf "a = %d, b = %d\n", a, b }'
a = 11, b = 11
التناقص:
يتم تمثيله بـ -- يقوم بعملية النقصان بمقدار 1، طريقة عمله هو إرجاع القيمة ثم الإنقاص.
awk 'BEGIN { a = 10; b = a--; printf "a = %d, b = %d\n", a, b }'
a = 9, b = 10
التناقص المسبق:
يتم تمثيله بـ -- يقوم بعملية النقصان بمقدار 1، طريقة عمله هو الإنقاص ثم إرجاع القيمة المتناقصة.
awk 'BEGIN { a = 10; b = --a; printf "a = %d, b = %d\n", a, b }'
a = 9, b = 9
معاملات الإسناد:
إسناد القيمة:
awk 'BEGIN { name = "Ahmed"; print "My name is", name }'
My name is Ahmed
الإسناد مع الجمع:
يتم تمثيله بـ +=.
awk 'BEGIN { cnt = 10; cnt += 10; print "Counter =", cnt }'
Counter = 20
الإسناد مع الطرح:
يتم تمثيله بـ -=.
awk 'BEGIN { cnt = 100; cnt -= 10; print "Counter =", cnt }'
Counter = 90
الإسناد مع الضرب:
يتم تمثيله بـ *=.
awk 'BEGIN { cnt = 10; cnt *= 10; print "Counter =", cnt }'
Counter = 100
الإسناد مع القسمة:
يتم تمثيله بـ /=.
awk 'BEGIN { cnt = 100; cnt /= 5; print "Counter =", cnt }'
Counter = 20
الإسناد مع باقي القسمة:
يتم تمثيله بـ %=.
awk 'BEGIN { cnt = 100; cnt %= 8; print "Counter =", cnt }'
Counter = 4
الإسناد مع القوة (الأس):
يتم تمثيله بـ ^= أو **=.
awk 'BEGIN { cnt = 2; cnt ^= 4; print "Counter =", cnt }'
awk 'BEGIN { cnt = 2; cnt **= 4; print "Counter =", cnt }'
Counter = 16
معاملات القيم المنطقية:
معامل Equal to:
يتم تمثيله بـ ==.
awk 'BEGIN { a = 10; b = 10; if (a == b) print "a == b" }'
a == b
معامل Not Equal to:
يتم تمثيله بـ !=.
awk 'BEGIN { a = 10; b = 20; if (a != b) print "a != b" }'
a != b
معامل Less Than:
يتم تمثيله بـ <.
awk 'BEGIN { a = 10; b = 20; if (a < b) print "a < b" }'
a < b
معامل Less Than or Equal to:
يتم تمثيله بـ <=.
awk 'BEGIN { a = 10; b = 10; if (a <= b) print "a <= b" }'
a <= b
معامل Greater Than:
يتم تمثيله بـ >.
awk 'BEGIN { a = 10; b = 20; if (b > a ) print "b > a" }'
b > a
معامل Greater Than or Equal to:
يتم تمثيله بـ >=.
awk 'BEGIN { a = 10; b = 20; if (b > a ) print "b >= a" }'
b >= a
المعامل الثلاثي (إجراء الشرط في سطر واحد):
الصيغة النحوية تكون كالتالي:
condition expression ? statement1 : statement2
يتم إختبار الشرط إن كان صحيحاً يتم تنفيذ العبارة الأولى، وإلا يتم تنفيذ العبارة الثانية.
awk 'BEGIN { a = 10; b = 20; (a > b) ? max = a : max = b; print "Max =", max}'
Max = 20
دمج النصوص مع بعضها:
الفراغ Space هنا يمثل دمج النصوص.
awk 'BEGIN { str1 = "Hello, "; str2 = "World"; str3 = str1 str2; print str3 }'
Hello, World
المرور على عناصر المصفوفة:
يتم تمثيله بـ in يتم استخدامه للوصول إلى عناصر المصفوفة.
awk 'BEGIN {
arr[0] = 1; arr[1] = 2; arr[2] = 3; for (i in arr) printf "arr[%d] = %d\n", i, arr[i]
}'
arr[0] = 1
arr[1] = 2
arr[2] = 3
التعابير المنطقية:
التعبير Dot:
يستخدم لمطابقة الكلمات مع تعويض النقط. يطابق المثال التالي مع fin, fun, fan عوض النقطة بداخل الحرف المفقود من الكلمة.
echo -e "cat\nbat\nfun\nfin\nfan" | awk '/f.n/'
fun
fin
fan
التعبير Start of line:
يطابق بداية السطر، يطبع المثال التالي جميع الأسطر التي تبدأ بـ The.
echo -e "This\nThat\nThere\nTheir\nthese" | awk '/^The/'
There
Their
التعبير End of line:
يطابق نهاية السطر، يطبع المثال التالي جميع الأسطر التي تنتهي بـ n.
echo -e "knife\nknow\nfun\nfin\nfan\nnine" | awk '/n$/'
fun
fin
fan
التعبير Match character set:
يتم استخدامه لمطابقة حرف واحد فقط من بين مجموعة أحرف، المثال التالي يطابق Call و Tall ولكن لا يطابق Ball.
echo -e "Call\nTall\nBall" | awk '/[CT]all/'
Call
Tall
التعبير Exclusive set:
عكس التعبير السابق، ينفي مجموعة الأحرف الموجودة بين قوسين مربعين، أي لن يتم مطابقتها، المثال التالي يطابق Ball فقط.
echo -e "Call\nTall\nBall" | awk '/[^CT]all/'
Ball
التعبير Alteration:
يسمح الـ | بطباعة Call أو Ball أو الاثنين معاً إن توفروا في النص.
echo -e "Call\nTall\nBall\nSmall\nShall" | awk '/Call|Ball/'
Call
Ball
التعبير Zero or More Occurrence:
تستخدم * لإكمال الكلمة، في المثال التالي أي كلمة تبدأ بـ ca سيتم مطابقتها، أي الحرف اللي يسبق علامة النجمة حتى لو لم يكن موجود سيتم المطابقة.
echo -e "ca\ncat\ncatt" | awk '/cat*/'
ca
cat
catt
التعبير One or More Occurrence:
يطابق إن كان هذا الحرف مكرر أم لا، في المثال التالي يطابق أي سطر فيه 2 سواء كتب مرة واحدة أو أكثر.
echo -e "111\n22\n123\n234\n456\n222" | awk '/2+/'
echo -e "111\n22\n123\n234\n456\n222" | awk '/2/'
22
123
234
222
التعبير Grouping:
تستخدم الأقواس () للتجميع والمحرف | يستخدم للبدائل، المثال يطابق التعبير التالي مع الأسطر التي تحتوي على Apple Juice أو Apple Cake.
echo -e "Apple Juice\nApple Pie\nApple Tart\nApple Cake" | awk '/Apple (Juice|Cake)/'
Apple Juice
Apple Cake
إعادة توجيه المخرجات:
نحتاج هنا إعادة توجيه المخرجات إلى ملف نصي بدلاً من عرضه على شاشة Terminal.
الكتابة على الملف:
awk 'BEGIN { print "Hello, World !!!" > "/tmp/message.txt" }'
الإضافة على الملف:
awk 'BEGIN { print "Hello, World !!!" >> "/tmp/message.txt" }'
إرسال الخرج إلى برنامج آخر بواسطة Pipe.
awk 'BEGIN { print "hello, world !!!" | "tr [a-z] [A-Z]" }'
تنسيق المخرجات:
الطباعة في سطر جديد:
awk 'BEGIN { printf "Hello\nWorld\n" }'
Hello
World
طباعة tab بشكل أفقي:
awk 'BEGIN { printf "Sr No\tName\tSub\tMarks\n" }'
Sr No Name Sub Marks
طباعة tab بشكل عمودي:
awk 'BEGIN { printf "Sr No\vName\vSub\vMarks\n" }'
Sr No
Name
Sub
Marks
طباعة Backspace لمسح محرف للخلف:
awk 'BEGIN { printf "Field 1\bField 2\bField 3\bField 4\n" }'
Field Field Field Field 4
الطباعة من بداية السطر:
\r: بعد الطباعة، نقوم بإرجاع مؤشر الكتابة في أول السطر ونطبع القيمة التالية فوق القيمة الحالية.
awk 'BEGIN { printf "Field 1\rField 2\rField 3\rField 4\n" }'
Field 4